data.nozav.org
About
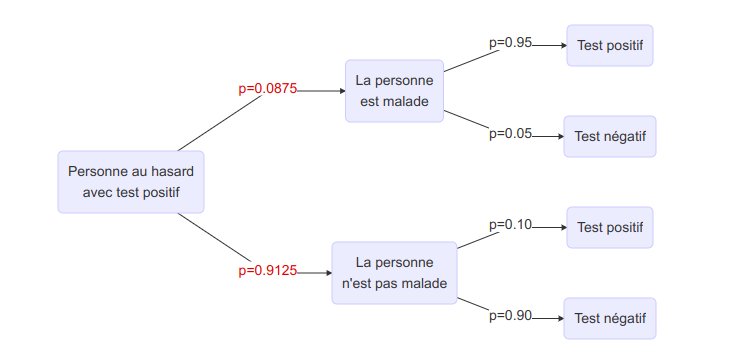
C’est quoi les Bayes ?
Je vais partir ici d’un exemple classique pour présenter (et réviser) quelques concepts de base de l’approche bayésienne en statistique. L’exemple en question sera celui…
2 juin 2021
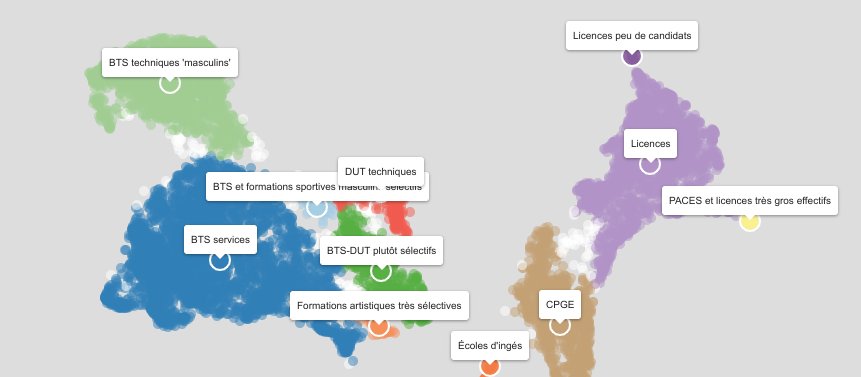
Classifions Parcoursup
Ce poste est archivé à l’adresse suivante : Classifions Parcoursup
20 janv. 2020
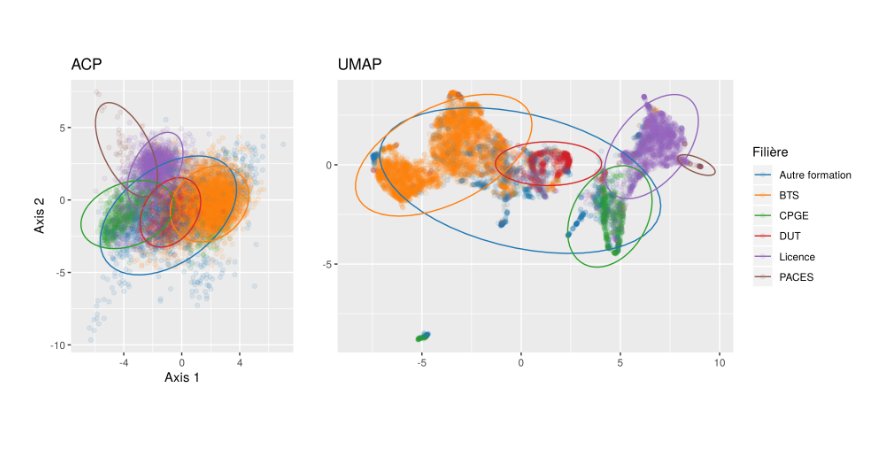
UMAP vs ACP vs Parcoursup
Ce poste est archivé à l’adresse suivante : UMAP vs ACP vs Parcoursup
11 déc. 2019
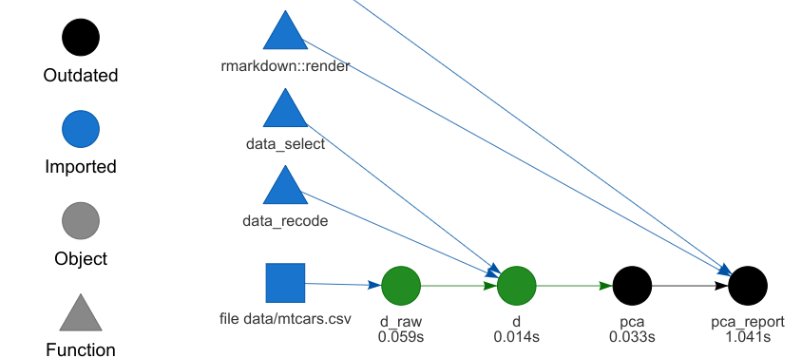
A short introduction to drake
The
drake
package has now been replaced by targets.
4 oct. 2019
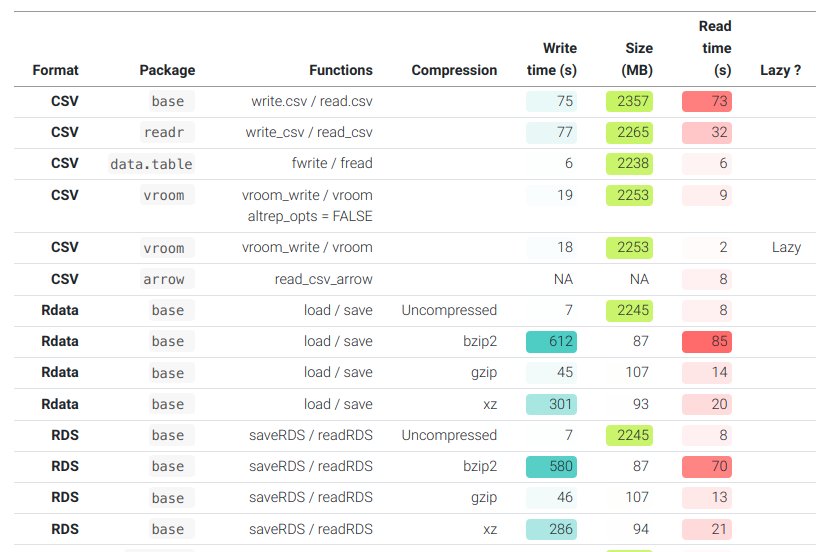
A shallow benchmark of R data frame export/import methods
There are several reasons why you would want to save a data frame to a file :
30 août 2019
Aucun article correspondant