Classifions Parcoursup
Attention : ce billet est méthodologiquement à la fois expérimental et sans doute discutable. À utiliser donc avec précaution…
Previously on Parcoursup
Ce post est la suite d’un précédent billet qui présente l’utilisation d’UMAP comme méthode de réduction de dimensionnalité appliquée aux données de la campagne 2018 de Parcoursup. Vous pouvez vous y référer pour avoir un aperçu du jeu de données et une brève (et peu convaincante) explication du fonctionnement d’UMAP.
On prend donc comme point de départ le résultat d’UMAP appliquée sur notre jeu de données avec les paramètres suivants1 :
library(tidyverse)
library(uwot)
set.seed(1337)
um <- umap(d, n_neighbors = 30, min_dist = 0, scale = "scale")
res_um <- tibble(x = um[,1], y = um[,2])On peut représenter graphiquement ce résultat :
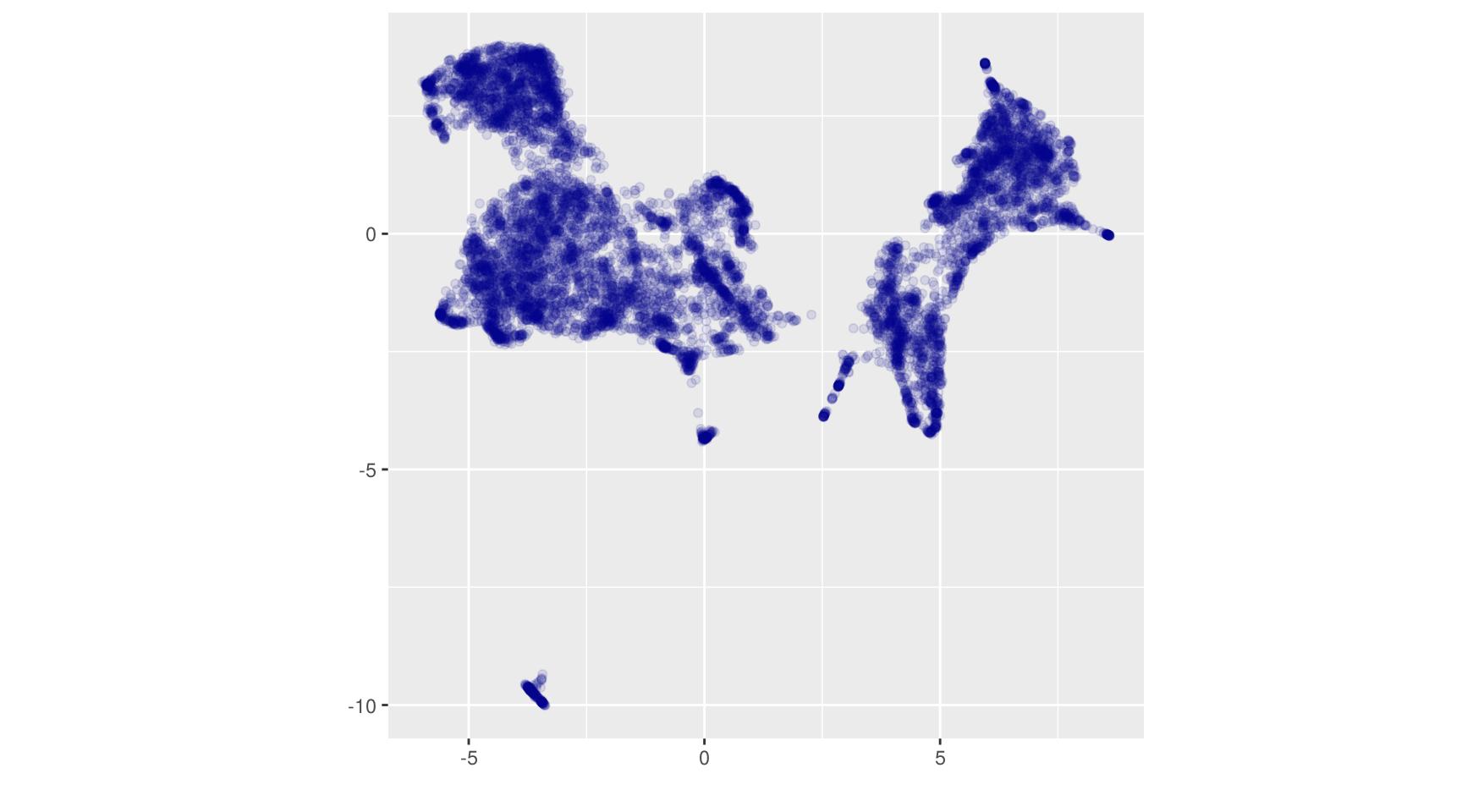
Le billet précédent s’arrêtait sur le constat qu’UMAP semble mettre en valeur des structures globales et locales de manière plus fine qu’une ACP. La question qui en découle étant celle de la classification : quelle méthode utiliser pour mettre en valeur ces groupes de manière un peu formelle ?
Ce qui tombe très bien, c’est que le site d’UMAP comporte justement une page nommée Using UMAP for Clustering.
Il faut garder en tête que l’usage de méthodes de clustering sur le résultat de méthodes de type UMAP ou t-SNE reste un sujet discuté. On pourra avoir un petit aperçu de ces discussions sur cette question sur StackOverflow.
Pour faire court, ceux qui s’y opposent pointent notamment que :
- ces méthodes ne préservent pas les distances, et pas tout à fait non plus les densités
- les paramètres d’entrée peuvent modifier considérablement les résultats obtenus, et donc les données sur lesquelles s’appliqueront la méthode de classification
- ces méthodes font parfois apparaître des structures locales de manière artificielle
D’un autre côté, certaines personnes ont une approche plus pragmatique et constatent qu’utiliser une méthode comme UMAP avant une classification fonctionne très bien dans certains cas, et peut considérablement améliorer les résultats par rapport à la même méthode de classification appliquée aux données brutes.
Ce qu’il faut retenir en tous cas c’est que, comme pour le choix des paramètres de UMAP, il ne faut pas appliquer ces méthodes à l’aveugle et toujours contrôler a posteriori la validité des groupes obtenus, ce qui nécessite notamment d’avoir une bonne connaissance des données traitées.
DBSCAN
Comme UMAP ne préserve absolument pas les distances entre les observations, la page Using UMAP for Clustering recommande plutôt d’utiliser DBSCAN, une méthode de classification basée sur la densité.
Cette méthode prend deux paramètres minPts et eps. Son principe est assez
simple :
- pour chaque point, on compte le nombre de ses voisins dans un rayon
eps. Si ce nombre est supérieur àminPts, alors le point fait partie d’un cluster et est considéré comme un core point. - on étend ce cluster à l’ensemble des autres core points situés à moins de
epsdu premier point. - quand le cluster a été étendu à l’ensemble des core points atteignables, on l’étend
également à tous les points qui ne sont pas des core points mais qui sont à moins de
epsd’un core point du cluster. - on recommence avec chacun des points non précédemment visités lors d’une des étapes précédentes.
- à la fin, les points qui ne sont pas des core points et qui ne sont pas atteignables depuis un core point sont considérés comme isolés et n’appartiennent à aucun groupe.
Parmi les avantages de DBSCAN, on peut noter que :
- les calculs sont rapides
- on n’a pas besoin de spécifier à l’avance le nombre de clusters
- il est possible d’identifier des clusters quelle que soit leur forme
- la méthode est robuste, les points isolés n’étant inclus dans aucun cluster
Le principal inconvénient est que les résultats dépendent beaucoup de la valeur de eps, et
que DBSCAN n’est pas capable de trouver des clusters de densité différente : on pourra identifier les
structures globales ou les structures locales, mais pas les deux en même temps.
Essai d’application à Parcoursup
On va appliquer DBSCAN à nos données grâce à la fonction dbscan du package…
dbscan.
La valeur de minPts est parfois fixée au nombre de dimensions de nos données plus un (on
peut aussi utiliser une valeur plus grande). On commence donc avec minPts = 3 et une valeur
de eps plutôt élevée :
library(dbscan)
cl <- dbscan(res_um, minPts = 3, eps = 0.5)Et on représente graphiquement les clusters obtenus :
.tmp <- bind_cols(res_um, cluster = factor(cl$cluster))
ggplot(.tmp, aes(x = x, y = y, col = cluster)) +
geom_point(alpha = 0.1) +
ggsci::scale_color_d3("category20", alpha = 1) +
coord_fixed() +
xlab("") +
ylab("")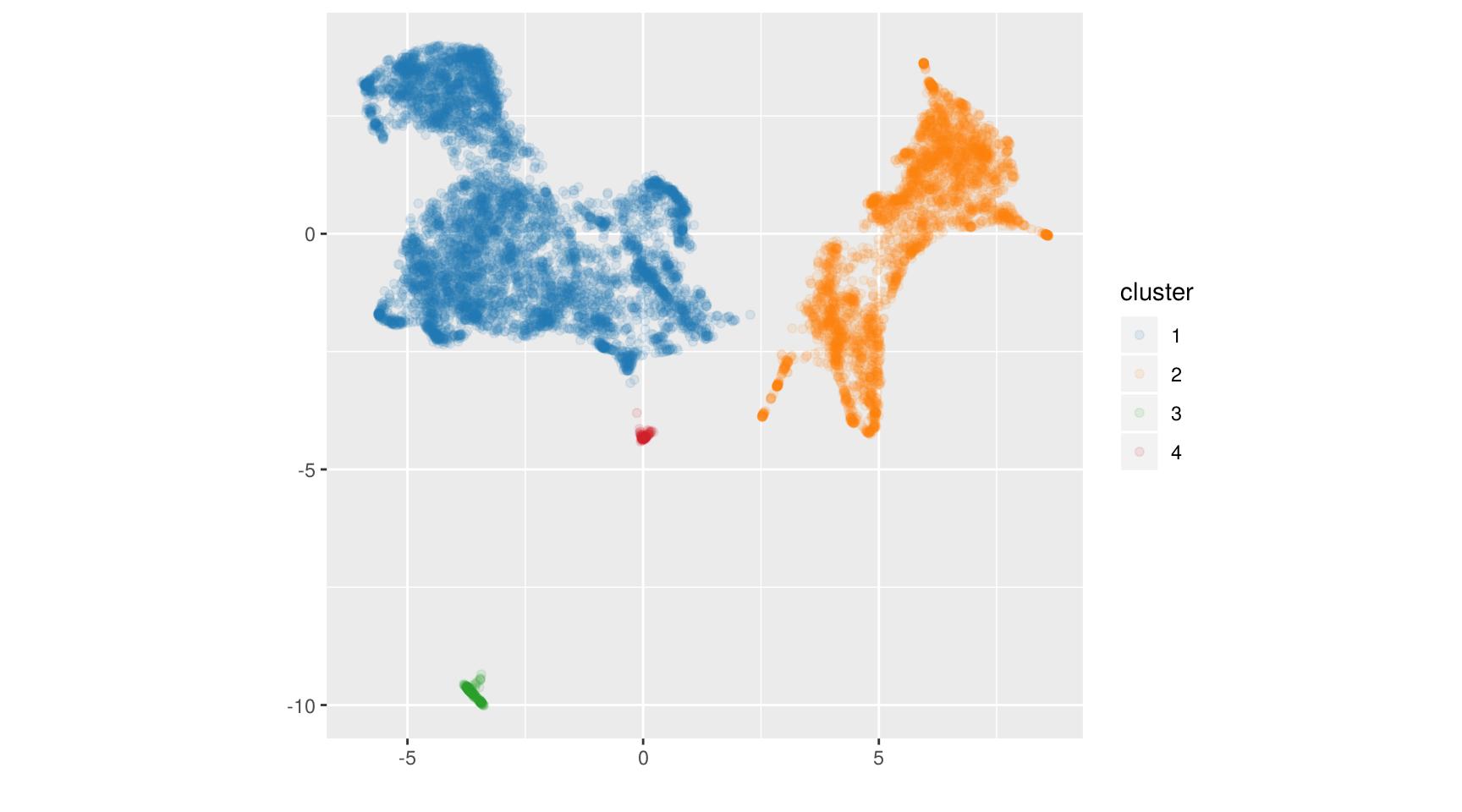
On voit qu’avec cette valeur d’eps on arrive à identifier 4 groupes qui se détachent par
ailleurs assez bien visuellement. On perd par contre toutes les structures locales à l’intérieur de ces
groupes.
Essayons avec une valeur d’eps plus faible :
cl <- dbscan(res_um, minPts = 3, eps = 0.2)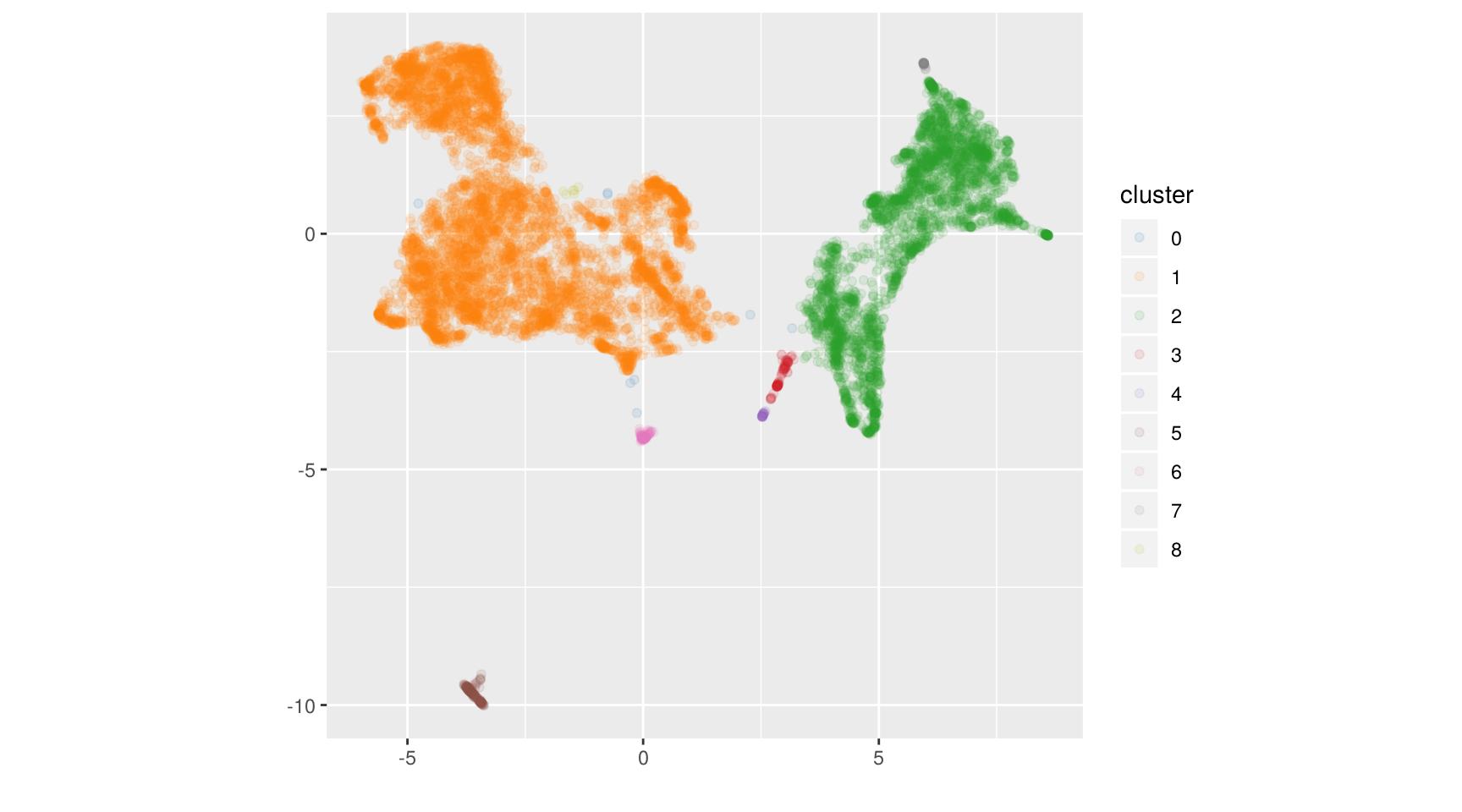
Ici on arrive à identifier davantage de structures locales, mais pas toutes. Et on se retrouve avec
certains points non classifiés : en effet, dans le résultat de dbscan, le cluster identifié
0 comporte tous les points isolés.
Essayons avec une valeur d’eps encore plus faible :
cl <- dbscan(res_um, minPts = 3, eps = 0.1)## Warning: This manual palette can handle a maximum of 20 values. You have
## supplied 72.## Warning: Removed 438 rows containing missing values (geom_point).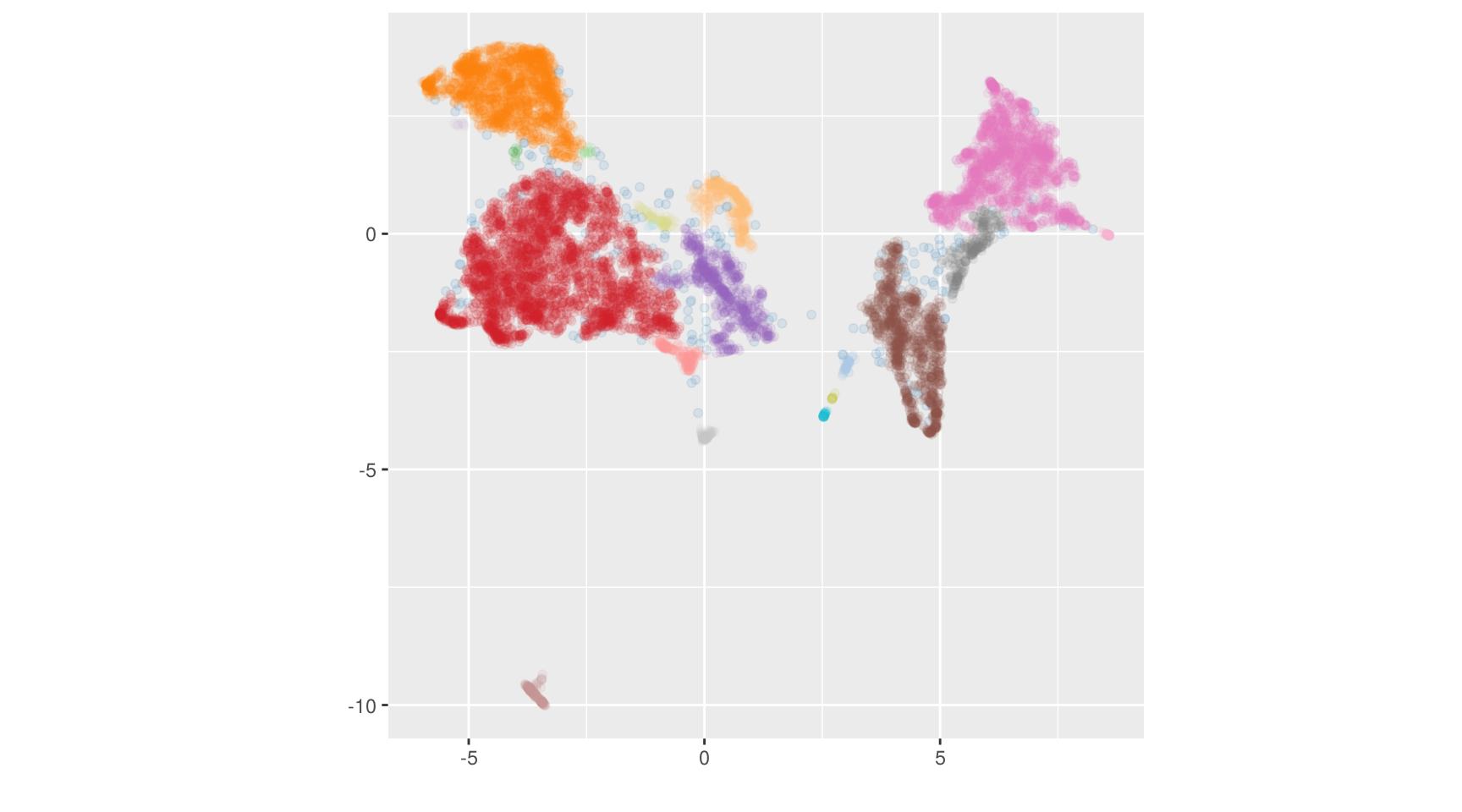
On se retrouve cette fois avec 72 clusters, dont tous n’ont pas pu être représentés faute de couleurs. La plupart des clusters sont très petits, puisque 30 d’entre eux comportent moins de 5 points.
On se heurte donc ici à la principale limite de DBSCAN : la valeur du paramètre eps permet
de faire varier le clustering entre structures globales et structures locales, mais si les données
comportent des clusters de densités différentes il n’existe pas d’unique valeur de eps
permettant de les identifier tous.
C’est pourquoi nous proposons ici d’effectuer une classification itérative,
hiérarchique, manuelle et pragmatique en utilisant DBSCAN à plusieurs
reprises avec des valeurs d’eps différentes.
umapscan
Pour faciliter ce travail de classification, nous avons mis en place un package R nommé umapscan. Attention, celui-ci est encore très expérimental.
Initialisation
Pour l’utiliser, on commence par créer un nouvel objet de type umapscan avec la fonction
new_umapscan :
d_sup <- d_orig %>% select(g_ea_lib_vx, dep_lib, fili, fil_lib_voe_acc, form_lib_voe_acc)
library(umapscan)
us <- new_umapscan(
d, n_neighbors = 30, min_dist = 0.0, scale = "scale",
seed = 1337, data_sup = d_sup
)- Les arguments
n_neighbors,min_distetscalesont passés directement à la fonctionumapdeuwot. - L’argument
seedpermet d’initialiser le générateur de nombres aléatoires avec une valeur fixée avant chaque opération non déterministe, permettant une reproductibilité des résultats obtenus. - L’argument
data_suppermet de passer des données supplémentaires qui pourront être utilisées notamment pour la visualisation des résultats.
En appliquant la fonction plot à un objet umapscan on peut facilement
représenter le résultat de umap, et si besoin colorer les points selon l’une des
variables dans nos données utilisées pour les calculs ou passées via data_sup.
Ici on représente, comme dans le billet précédent, la répartition des filières de formation :
plot(us, color = fili, ellipses = TRUE, fixed = TRUE)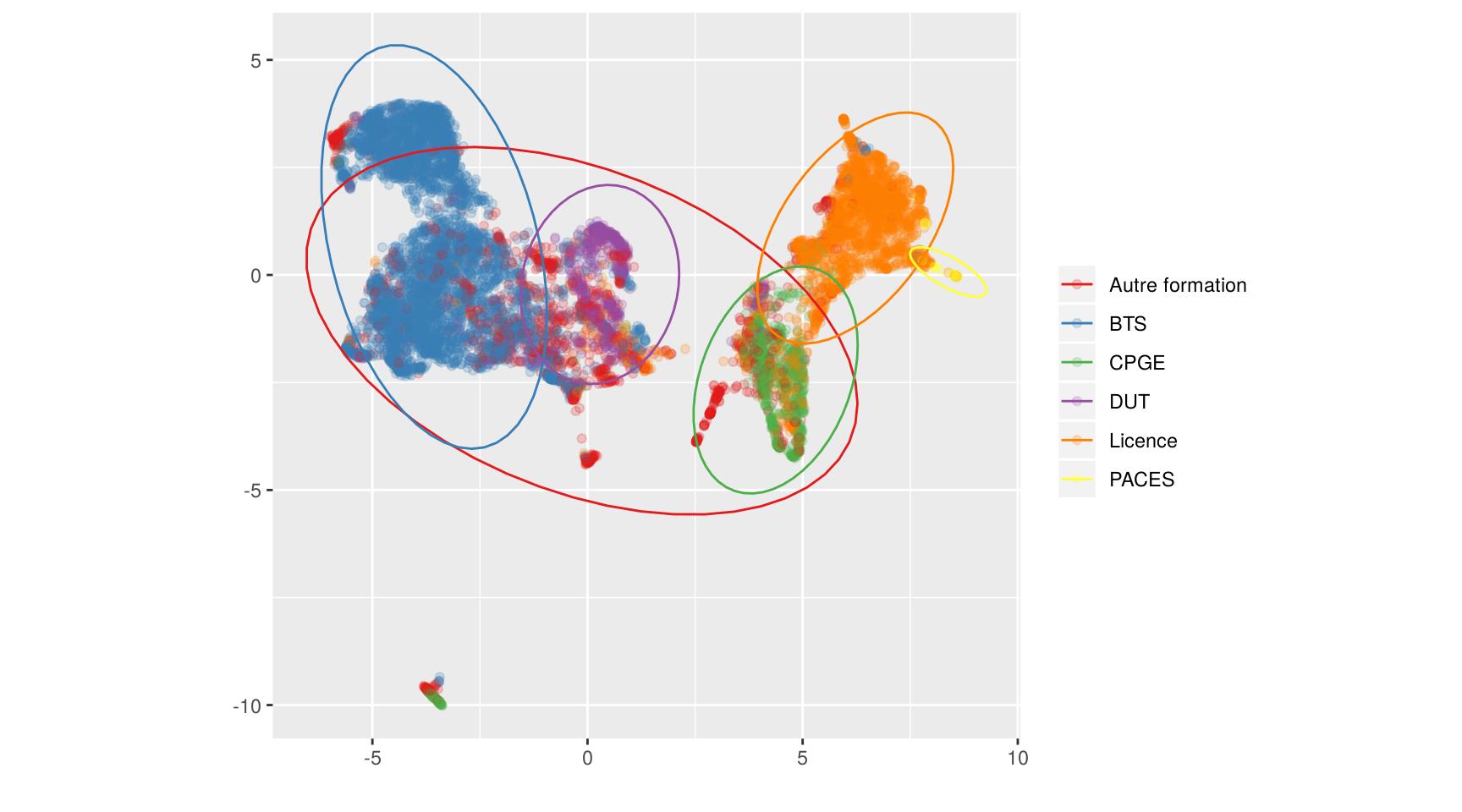
Premier clustering
Notre objet us, de classe umapscan, est une liste comportant plusieurs
éléments dont un nommé clusters qui pour l’instant est vide :
us##
## Call: new_umapscan(d = d, n_neighbors = 30, min_dist = 0, scale = "scale",
## seed = 1337, data_sup = d_sup)
##
## UMAP embeddings of a 10689x20 data frame
## with a 10689x5 data frame of supplementary data
##
## Clusters : <none>On va donc lancer un premier clustering avec la fonction compute_clusters. Celle-ci
prend notamment en argument les paramètres minPts et eps qui seront passés à
dbscan :
us <- compute_clusters(us, minPts = 3, eps = 0.5, alpha = 0.1)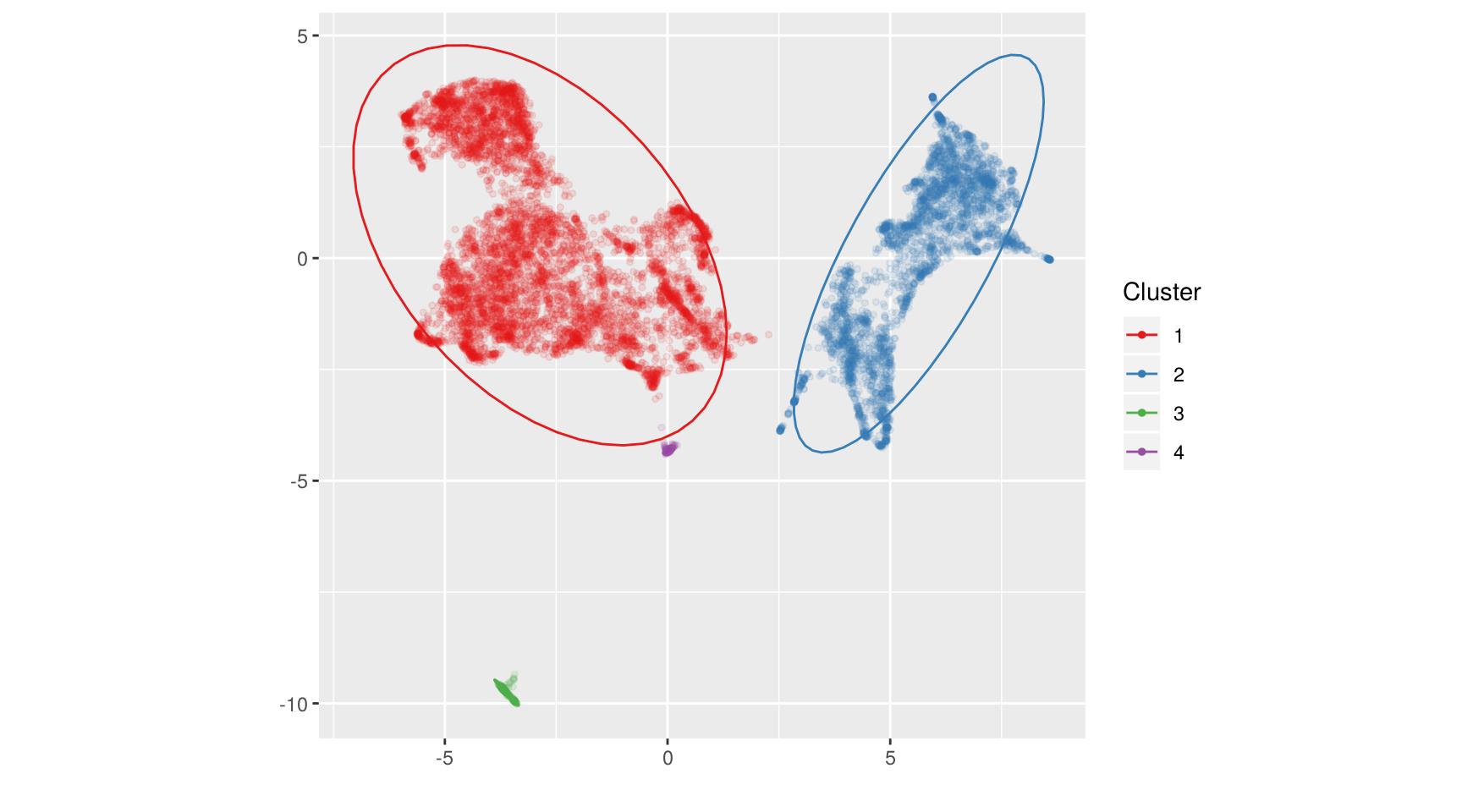
La fonction génère une visualisation des clusters obtenus, et a mis à jour l’élément
clusters de notre objet :
us##
## Call: new_umapscan(d = d, n_neighbors = 30, min_dist = 0, scale = "scale",
## seed = 1337, data_sup = d_sup)
##
## UMAP embeddings of a 10689x20 data frame
## with a 10689x5 data frame of supplementary data
##
## Clusters :
##
## levelName
## 1
## 2 ¦--1
## 3 ¦--2
## 4 ¦--3
## 5 °--4Nous avons donc 4 clusters, mais à quoi correspondent-ils ?
describe_clusters(us)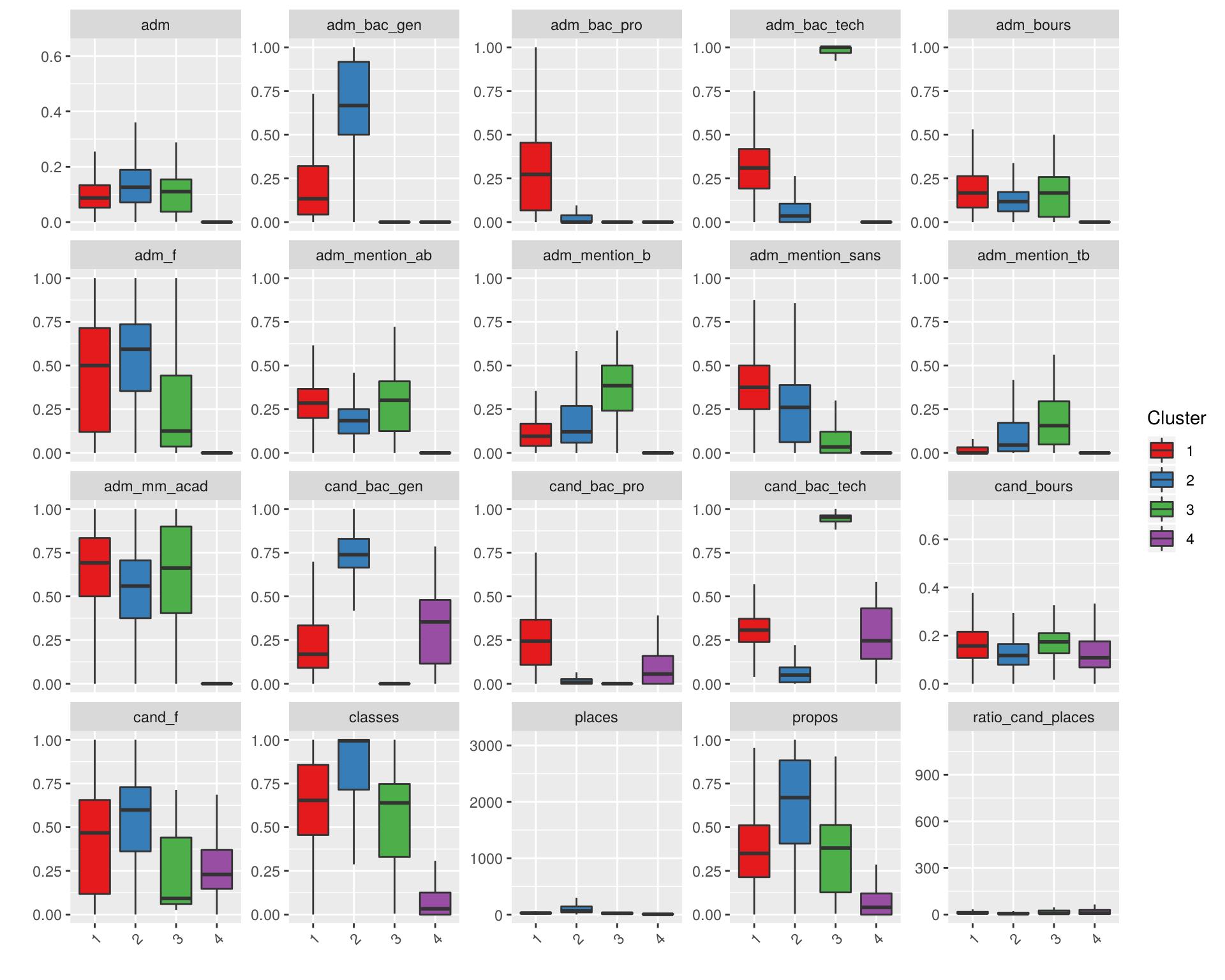
Pour avoir étudié la répartition par filières précédemment, on sait que le groupe 1 comprend la plupart des BTS et DUT, tandis que le groupe 2 correspond aux licences et CPGE. On le repère notamment dans le type de bac des candidats et des admis. Quant au groupe 3, il se caractérise par un recrutement quasi exclusif de bacheliers technologiques, un recrutement plutôt sélectif, et globalement très peu de filles. Le groupe 4 enfin, est constitué de formations n’ayant admis quasiment aucun candidat.
On peut utiliser get_cluster_data pour récupérer les données des observations du groupe
3 (les données d’origine ainsi que celles passées en argument data_sup sont affichées
ensemble) :
get_cluster_data(us, "3")On voit donc que ce groupe comprend des formations sélectives, notamment des CPGE et formations d’ingénieurs, recrutant surtout des bacheliers technologiques, notamment dans les domaines industriels.
On fait de même pour le groupe 4 :
get_cluster_data(us, "4")Ce groupe comprend des formations avec très peu d’admis et de classés (voire aucun), et comprend notamment des filières assez spécifiques : filières sportives, artistiques, quelques formations d’ingénieur…
Maintenant qu’on a (à peu près) identifié nos groupes, on va les nommer à l’aide de
rename_cluster :
us <- us %>%
rename_cluster("1", "BTS-DUT") %>%
rename_cluster("2", "Licences-CPGE") %>%
rename_cluster("3", "Filières techno sélectives") %>%
rename_cluster("4", "Spécifique, très peu d'admis")us##
## Call: new_umapscan(d = d, n_neighbors = 30, min_dist = 0, scale = "scale",
## seed = 1337, data_sup = d_sup)
##
## UMAP embeddings of a 10689x20 data frame
## with a 10689x5 data frame of supplementary data
##
## Clusters :
##
## levelName
## 1
## 2 ¦--BTS-DUT
## 3 ¦--Filières techno sélectives
## 4 ¦--Licences-CPGE
## 5 °--Spécifique, très peu d'admisOn a donc un premier niveau de classification. Mais si un groupe comme “Filières techno sélectives” est plutôt bien défini, les groupes “BTS-DUT” et “Licences-CPGE” sont évidemment très hétérogènes.
Classification du groupe “Licences-CPGE”
On va donc effectuer une seconde classification, mais en ne prenant en compte qu’une seule des catégories précédentes, pour essayer d’aller un peu plus loin dans sa description.
Pour cela on va appeler à nouveau compute_clusters, mais en lui passant comme argument
parent le nom du groupe sur lequel appliquer cette nouvelle classification.
us <- compute_clusters(us, parent = "Licences-CPGE", minPts = 15, eps = 0.2)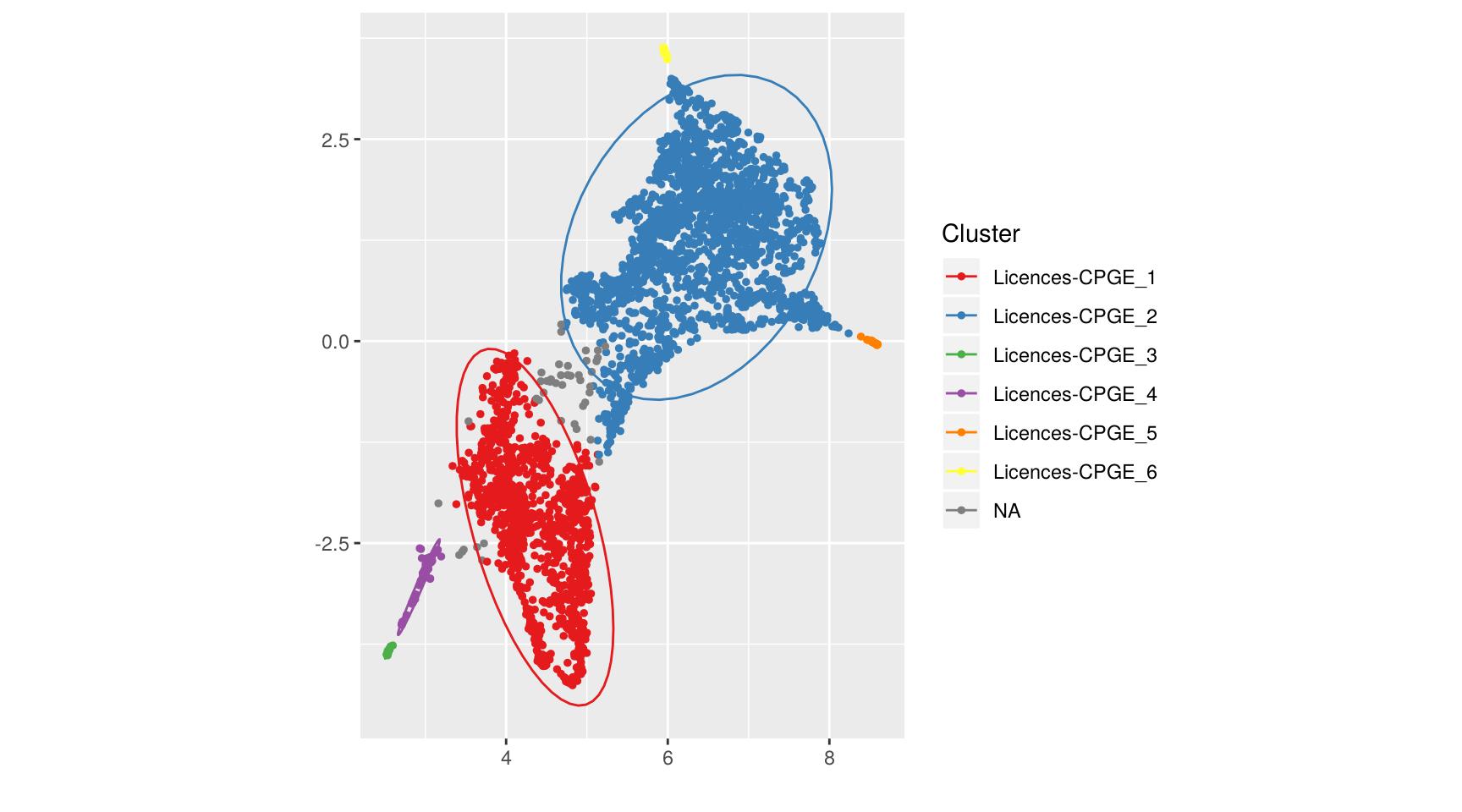
Le graphique affiché ne représente que les points du groupe précédent “Licences-CPGE”. L’élément
clusters a été mis à jour avec ces nouveaux sous-groupes, et il indique et conserve la
hiérarchie des clusters définis :
us##
## Call: new_umapscan(d = d, n_neighbors = 30, min_dist = 0, scale = "scale",
## seed = 1337, data_sup = d_sup)
##
## UMAP embeddings of a 10689x20 data frame
## with a 10689x5 data frame of supplementary data
##
## Clusters :
##
## levelName
## 1
## 2 ¦--BTS-DUT
## 3 ¦--Filières techno sélectives
## 4 ¦--Licences-CPGE
## 5 ¦ ¦--Licences-CPGE_1
## 6 ¦ ¦--Licences-CPGE_2
## 7 ¦ ¦--Licences-CPGE_4
## 8 ¦ ¦--Licences-CPGE_3
## 9 ¦ ¦--Licences-CPGE_5
## 10 ¦ ¦--Licences-CPGE_6
## 11 ¦ °--<Noise>
## 12 °--Spécifique, très peu d'admisOn peut décrire ces sous-groupes avec describe_clusters, en ajoutant là aussi un
argument parent :
describe_clusters(us, parent="Licences-CPGE")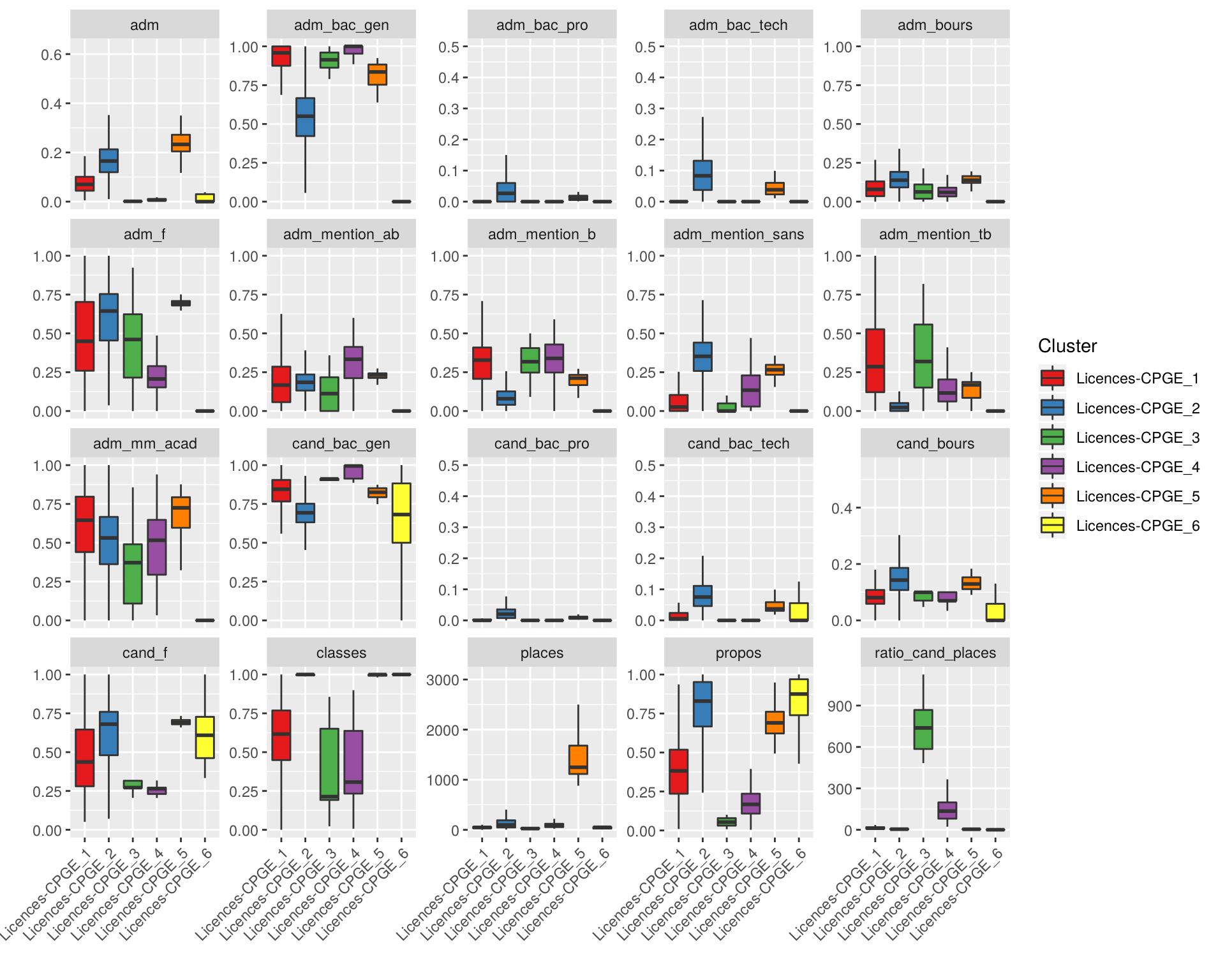
On sait d’après le graphique par filières que le groupe 2 correspond plutôt aux licences, moins sélectives et qui classent systématiquement tous les candidats, tandis que le groupe 1 comprend plutôt les CPGE.
Les groupes 3 et 4 semblent avoir un profil assez spécifique, avec une sélectivité forte, une porportion de filles faible, et surtout un ratio candidats / places élevé. Si on regarde les formations composant ces groupes, on trouve quasi exclusivement des écoles d’ingénieurs.
Le groupe 5 correspond à des formations avec énormément de places, et pas particulièrement sélectives. On y trouve essentiellement des PACES et des licences de droit ou de psychologie.
Enfin, le groupe 6 correspond à des licences, notamment de langues, avec peu de candidats, plutôt beaucoup de propositions mais très peu d’admis au final.
On nomme donc nos nouvelles classes. En attribuant le même nom aux groupes 3 et 4 on choisit de les regrouper dans une seule catégorie :
us <- us %>%
rename_cluster("Licences-CPGE_1", "CPGE") %>%
rename_cluster("Licences-CPGE_2", "Licences") %>%
rename_cluster("Licences-CPGE_3", "Écoles d'ingés") %>%
rename_cluster("Licences-CPGE_4", "Écoles d'ingés") %>%
rename_cluster("Licences-CPGE_5", "PACES et licences très gros effectifs") %>%
rename_cluster("Licences-CPGE_6", "Licences peu de candidats")Ce qui nous donne la hiérarchie suivante :
us##
## Call: new_umapscan(d = d, n_neighbors = 30, min_dist = 0, scale = "scale",
## seed = 1337, data_sup = d_sup)
##
## UMAP embeddings of a 10689x20 data frame
## with a 10689x5 data frame of supplementary data
##
## Clusters :
##
## levelName
## 1
## 2 ¦--BTS-DUT
## 3 ¦--Filières techno sélectives
## 4 ¦--Licences-CPGE
## 5 ¦ ¦--<Noise>
## 6 ¦ ¦--CPGE
## 7 ¦ ¦--Écoles d'ingés
## 8 ¦ ¦--Licences
## 9 ¦ ¦--Licences peu de candidats
## 10 ¦ °--PACES et licences très gros effectifs
## 11 °--Spécifique, très peu d'admisClassification du groupe “CPGE”
Continuons en étudiant le groupe “CPGE” :
us <- compute_clusters(us, parent = "CPGE", minPts = 20, eps = 0.15)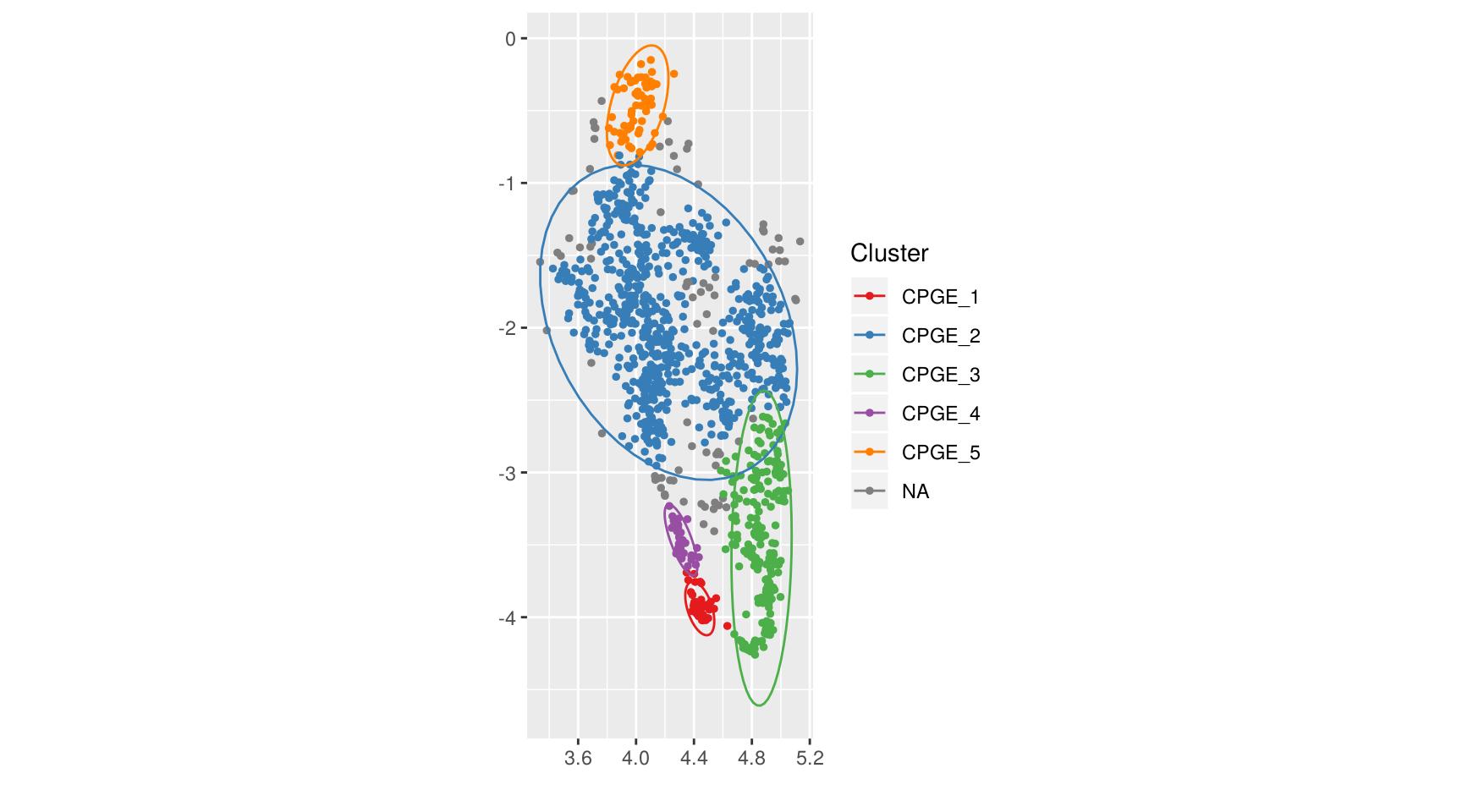
describe_clusters(us, parent = "CPGE")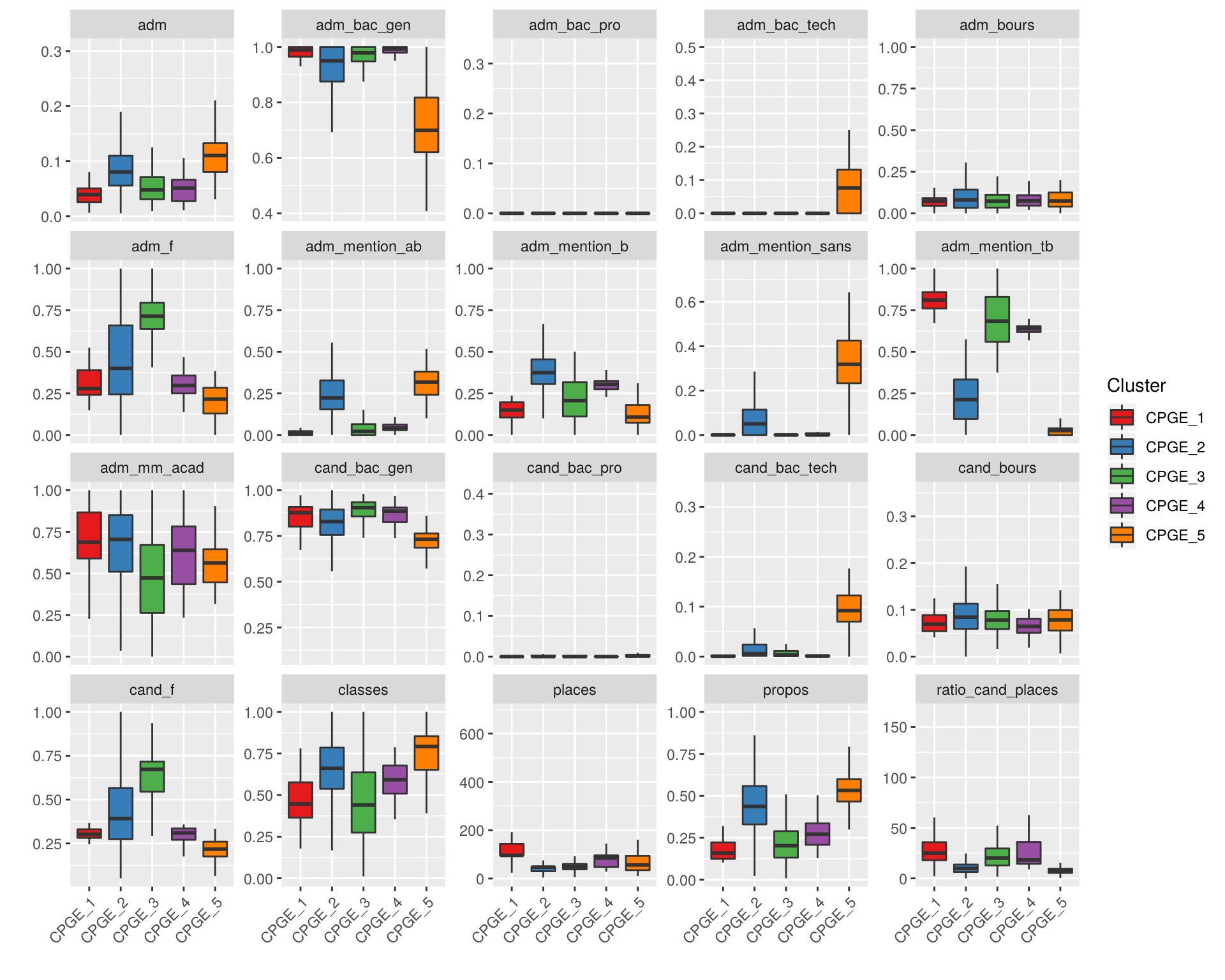
Les groupes 1 et 4 comportent des CPGE scientifiques très sélectives, parmi les plus prestigieuses. Le groupe 3 comporte des CPGE littéraires et économiques ainsi que quelques licences, toutes très sélectives avec une plus forte proportion de filles. Le groupe 5 comporte des CPGE moins sélectives, mais aussi à l’inverse des DUT ou licences scientifiques sélectifs. Enfin, le groupe 2 comprend les “Autres CPGE”.
us <- us %>%
rename_cluster("CPGE_1", "CPGE scientifiques très sélectives") %>%
rename_cluster("CPGE_4", "CPGE scientifiques très sélectives") %>%
rename_cluster("CPGE_3", "CPGE et licences lettres/éco très sélectives") %>%
rename_cluster("CPGE_2", "Autres CPGE") %>%
rename_cluster("CPGE_5", "CPGE moins sélectives, licences et DUT scientifiques sélectifs")On obtient donc la hiérarchie suivante :
us##
## Call: new_umapscan(d = d, n_neighbors = 30, min_dist = 0, scale = "scale",
## seed = 1337, data_sup = d_sup)
##
## UMAP embeddings of a 10689x20 data frame
## with a 10689x5 data frame of supplementary data
##
## Clusters :
##
## levelName
## 1
## 2 ¦--BTS-DUT
## 3 ¦--Filières techno sélectives
## 4 ¦--Licences-CPGE
## 5 ¦ ¦--<Noise>
## 6 ¦ ¦--CPGE
## 7 ¦ ¦ ¦--<Noise>
## 8 ¦ ¦ ¦--Autres CPGE
## 9 ¦ ¦ ¦--CPGE et licences lettres/éco très sélectives
## 10 ¦ ¦ ¦--CPGE moins sélectives, licences et DUT scientifiques sélectifs
## 11 ¦ ¦ °--CPGE scientifiques très sélectives
## 12 ¦ ¦--Écoles d'ingés
## 13 ¦ ¦--Licences
## 14 ¦ ¦--Licences peu de candidats
## 15 ¦ °--PACES et licences très gros effectifs
## 16 °--Spécifique, très peu d'admisClassification du groupe “Licences”
On poursuit la classification en se concentrant sur le groupe “Licences”.
us <- compute_clusters(us, parent = "Licences", minPts = 40, eps = 0.22)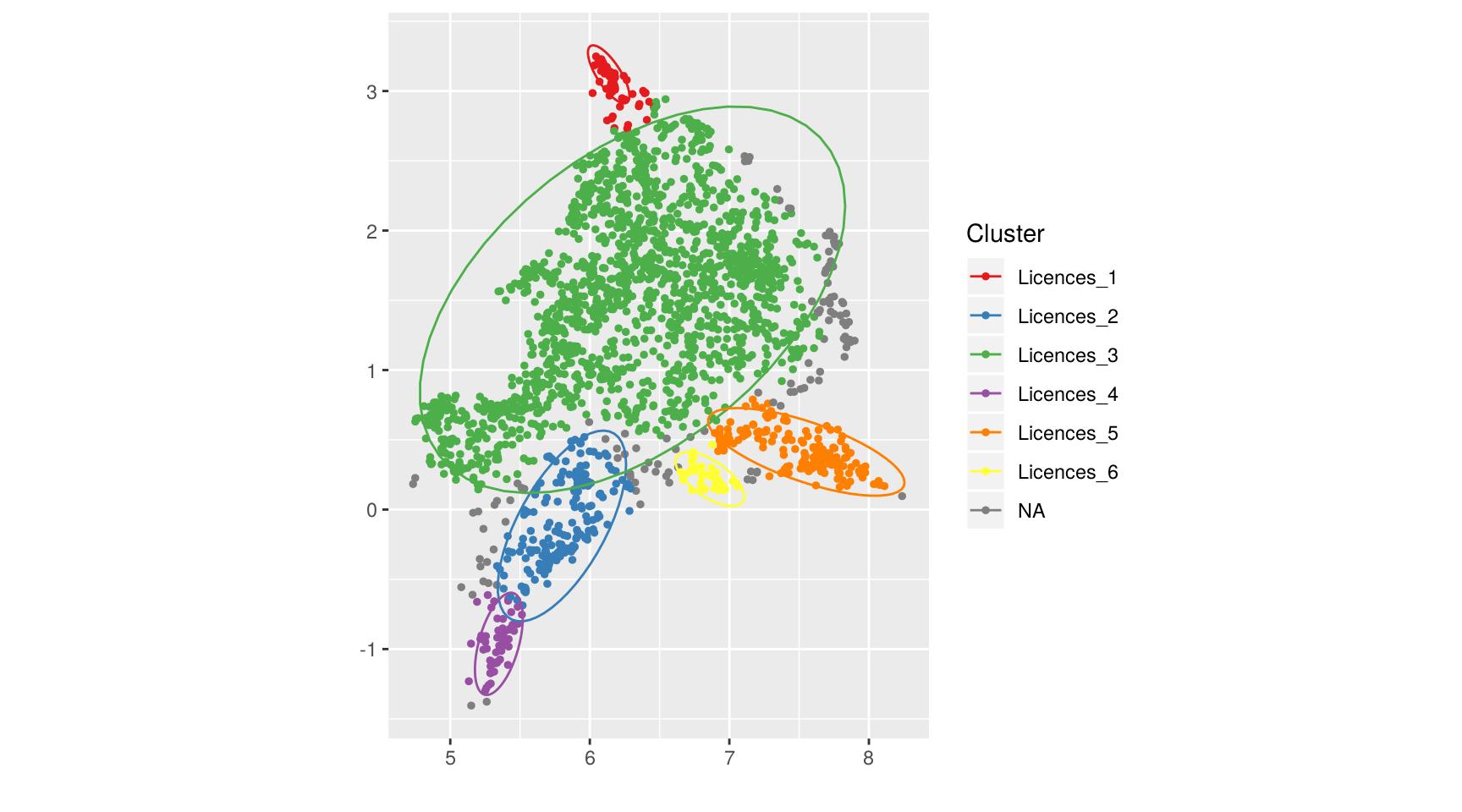
describe_clusters(us, parent = "Licences")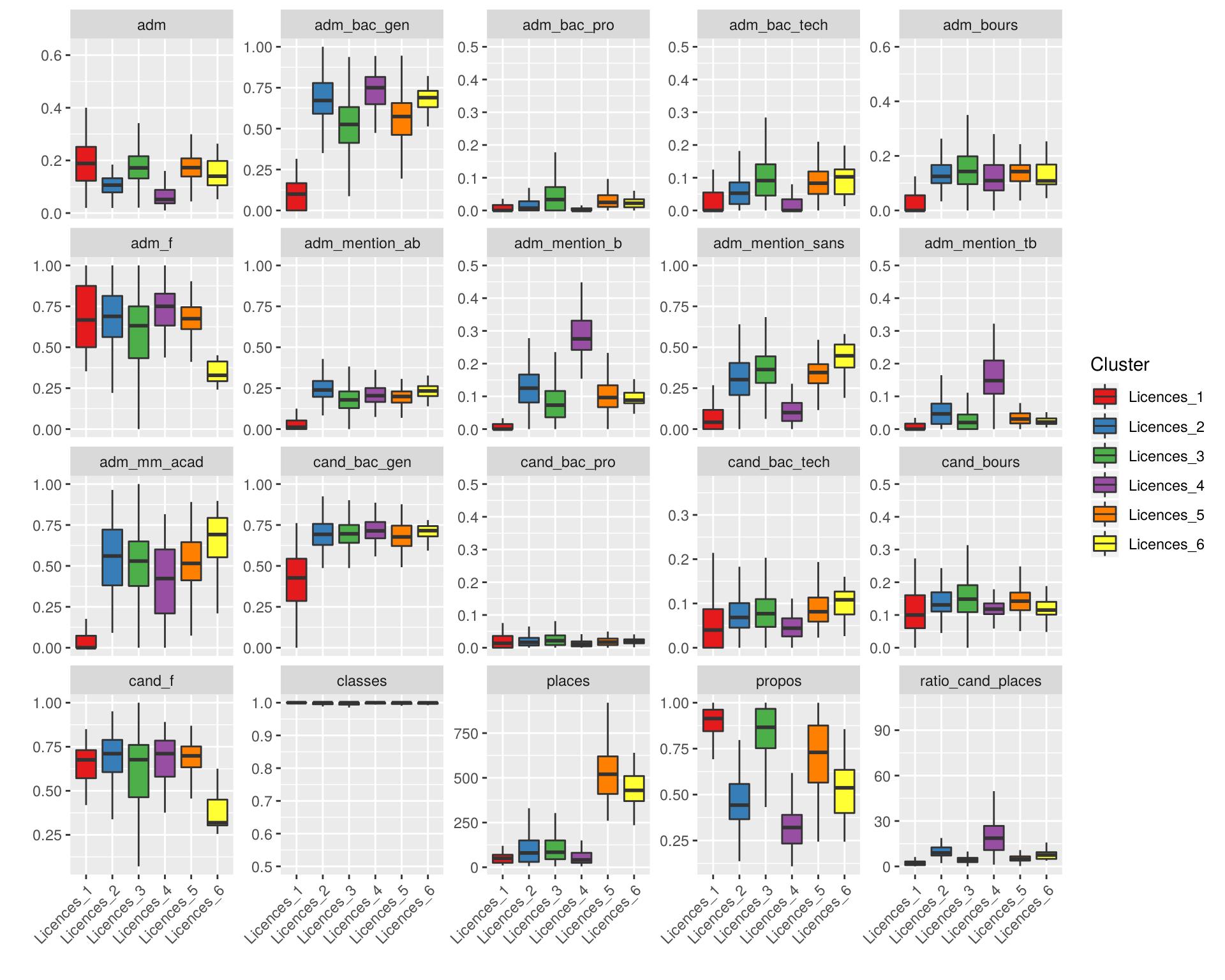
Le groupe 4 comporte des licences très sélectives, et le groupe 2 des licences sélectives. Le groupe 5 comprend des licences et quelques BTS avec beaucoup de places. Le groupe 1 comprend des licences littéraires, notamment de langues, avec des admis hors bac, souvent hors académie. Le groupe 3 correspond au reste des licences.
us <- us %>%
rename_cluster("Licences_4", "Licences très sélectives") %>%
rename_cluster("Licences_2", "Licences sélectives") %>%
rename_cluster("Licences_5", "Licences et BTS beaucoup de places") %>%
rename_cluster("Licences_6", "Licences beaucoup de places 'masculines'") %>%
rename_cluster("Licences_3", "Autres licences") %>%
rename_cluster("Licences_1", "Licences littéraires hors bac")Et ainsi de suite…
On applique la même méthode sur le groupe “BTS-DUT” qu’on décompose à son tour progressivement en différentes catégories.
Classification finale
La classification finale obtenue est la suivante. On finit par avoir un nombre de classes et un niveau de détail relativement élevé :
us##
## Call: new_umapscan(d = d, n_neighbors = 30, min_dist = 0, scale = "scale",
## seed = 1337, data_sup = d_sup)
##
## UMAP embeddings of a 10689x20 data frame
## with a 10689x5 data frame of supplementary data
##
## Clusters :
##
## levelName
## 1
## 2 ¦--BTS-DUT
## 3 ¦ ¦--<Noise>
## 4 ¦ ¦--BTS et formations sportives masculins sélectifs
## 5 ¦ ¦--BTS services
## 6 ¦ ¦ ¦--<Noise>
## 7 ¦ ¦ ¦--Autres BTS services
## 8 ¦ ¦ ¦--BTS services DOM boursiers
## 9 ¦ ¦ ¦--BTS services sélectifs
## 10 ¦ ¦ °--BTS services sélectifs hors acad
## 11 ¦ ¦--BTS techniques 'masculins'
## 12 ¦ ¦ ¦--<Noise>
## 13 ¦ ¦ ¦--Autres BTS techniques 'masculins'
## 14 ¦ ¦ ¦--BTS techniques bac pro
## 15 ¦ ¦ ¦--BTS techniques DOM boursiers
## 16 ¦ ¦ °--BTS techniques mixtes plus sélectifs
## 17 ¦ ¦--BTS-DUT plutôt sélectifs
## 18 ¦ ¦--DUT techniques
## 19 ¦ °--Formations artistiques très sélectives
## 20 ¦--Filières techno sélectives
## 21 ¦--Licences-CPGE
## 22 ¦ ¦--<Noise>
## 23 ¦ ¦--CPGE
## 24 ¦ ¦ ¦--<Noise>
## 25 ¦ ¦ ¦--Autres CPGE
## 26 ¦ ¦ ¦--CPGE et licences lettres/éco très sélectives
## 27 ¦ ¦ ¦--CPGE moins sélectives, licences et DUT scientifiques sélectifs
## 28 ¦ ¦ °--CPGE scientifiques très sélectives
## 29 ¦ ¦--Écoles d'ingés
## 30 ¦ ¦--Licences
## 31 ¦ ¦ ¦--<Noise>
## 32 ¦ ¦ ¦--Autres licences
## 33 ¦ ¦ ¦--Licences beaucoup de places 'masculines'
## 34 ¦ ¦ ¦--Licences et BTS beaucoup de places
## 35 ¦ ¦ ¦--Licences littéraires hors bac
## 36 ¦ ¦ ¦--Licences sélectives
## 37 ¦ ¦ °--Licences très sélectives
## 38 ¦ ¦--Licences peu de candidats
## 39 ¦ °--PACES et licences très gros effectifs
## 40 °--Spécifique, très peu d'admisumpascan propose de représenter cette hiérarchie de catégories via un graphique de type
leaflet grâce à la fonction map_plot. Il est possible de zoomer et de choisir
un “niveau” de catégories, du plus global au plus détaillé. Enfin, via l’argument
point_labels on affiche au survol de chaque point son nom et son type de formation :
point_labels <- glue::glue(
"{us$data_sup$g_ea_lib_vx} ({us$data_sup$dep_lib}) <br />",
"{us$data_sup$fili} - {us$data_sup$form_lib_voe_acc} <br />",
"{us$data_sup$fil_lib_voe_acc}"
)
map_plot(us, point_labels = point_labels)Conclusion
Cette première tentative d’utilisation d’UMAP comme réduction de dimensionnalité suivie d’une série de classifications avec DBSCAN est éminemment imparfaite.
La plus grosse critique qu’on pourra lui adresser est sans doute le caractère très “artisanal et subjectif” du découpage en classes. En fonction des paramètres passés à DBSCAN on obtient des catégories qui peuvent être très différentes. Le choix se fait donc essentiellement par essai/erreur, selon l’interprétabilité des résultats obtenus. Il est donc nécessaire d’avoir une bonne connaissance des données : quelqu’un de bien plus au fait que moi des différents types de formation existantes aurait sans doute eu un résultat plus pertinent tant dans le choix que dans la description des catégories.
Pour autant, cet aspect éminemment subjectif peut aussi être vertueux : on pourrait en effet objecter qu’il est toujours plus ou moins présent, y compris dans d’autres méthodes de classification plus “formelles” type CAH ou k-means. Au moins, dans le cas présent, il est visible et assumé.
Enfin, on pourra quand même remarquer la capacité du couple UMAP + DBSCAN à faire resortir des catégories très globales bien séparées les unes des autres (les grands types de filières de formation), tout en arrivant à mettre en évidence des sous-groupes avec des spécificités fortes. Il n’est pas sûr que les méthodes de réduction-classification usuelles parviennent à mettre aussi bien en évidence à la fois des structures globales et locales. Son utilisation notamment dans des phases exploratoires pourrait donc être particulièrement intéressante.
-
On initialise préalablement le générateur de nombres aléatoires avec
set.seedpour garantir la reproductibilité des résultats, UMAP étant non déterministe.↩